Resources
| What & Link | Type |
|---|---|
| My Favorite Sources (Links to other cheatsheets and dev learning resources) | Collection |
Dependency Injection
Dependence Injection, often just referred to as "DI", is a common concept in OOP languages, and especially in frameworks. It tends to get over-complicated, but a basic view is this:
Rather than your class/object creating the thing it depends on (DB Driver, Session Manager, etc), it takes it as part of its setup (constructor or setter).
This reversal of who is in control is also why DI is often referred to as a type of Inversion of Control Container or IoC.
Resources for learning:
In practical use:
Most often, DI in OOP means that your class takes another class, either as an argument in the constructor, or via a setter function. That's it in a nutshell.
class User {
manager: UserManager;
// This is the important part:
constructor(usrMgr: UserManager){
// Notice we are *not* using the "new" keyword; we take an already instantiated class/object
this.manager = usrMgr;
}
public updateName(name: string){
this.manager.updateInDb(name);
}
}Why it matters / importance
There are a bunch of reasons why DI is popular and has a significant impact on how a program works.
- Isolation and Decoupling: Your code does not need to know the implementation details of the things it relies on
- All your code cares about is the interface and not the actual implementation details
- This means that dependencies can be easily swapped out without your code caring
- If the implementation and/or construction of the depenency changes, your code is not affected (as long as the interface stays the same)!
- Complexity: The isolation that DI provides and level of abstraction means that your own code can be less complex
- Your class doesn't need as much knowledge about the things it uses
- Frameworks: This really goes back to the isolation and decoupling benefits, but in a framework, DI means that your class can be auto-injected with complex framework pieces without caring about the details
- Also important as Frameworks update behind-the-scenes code; you don't have to update your classes, even if dependency stuff changes, because you are no longer responsible for creating those dependencies!
- Frameworks also often provide Dependency Injection Containers (more on that later)
- Testing: Complex classes can be more easily mocked (and injected) for automated testing
- If your class depends on another class, which depends on another, which depends on... that is going to get very complicated to manually mock
- With DI, in your tests, you can inject mocked versions of the things you need.
- Again, since DI just cares about the interface, the mocked dependency does not need to be "full-featured"
- Isolation, Decoupling, Seperation of Concerns, and the Dependency Inversion Principle:
- In my mind, these all say similar things, and kind of wrap up the benefits of everything above.
- In short, to me, DI is all about moving the responsibility of required links.
- Without DI, you are creating links to what you need inside your class logic, and you have to know how to create the things you need before you chain yourself to them. Not only that, but you have to know where to attach multiple chains at multiple points.
- With DI, other code is handing you exactly what you need with a handy leash already attached.
Dependency Injection Container
This is more advanced, so stop reading and review the previous sections if you don't yet understand the basics of DI.
DI, without any special setup, means that you still need some special setup, you are just reducing the amount of setup required and where it happens. But still, if your class has dependencies, then to construct your classes, the code calling it needs to provide the thing to be injected. If you have lots of things to inject, or they are highly complicated, this can make DI still complicated.
Dependency Injection Containers are a way to simplify this mapping of what your class needs to its creation. Essentially a container is responsible for:
- Tracking what you need injected
- Injecting it
- Reduce overhead (usually): re-use dependency if it already exists before injecting (singleton pattern)
Examples and further reading:
MVC (Model-View-Controller)
Resources
| What & Link | Type |
|---|---|
| Chrome Dev - App Frameworks - MVC | Guide |
| Essential JS Design Patterns - MVC Section | Ebook Section |
| TodoMVC - Examples of MVC pattern in various frameworks / langs | Examples |
| Node Express - official example | Example |
Diagrams
- Wikipedia (also embedded below)
- FreeCodeCamp - Web based, with routing
- MDN - Web based, with routing
Quick overview
A pattern for separating code by area of concern, which can be represented at its most basic level by this structure:
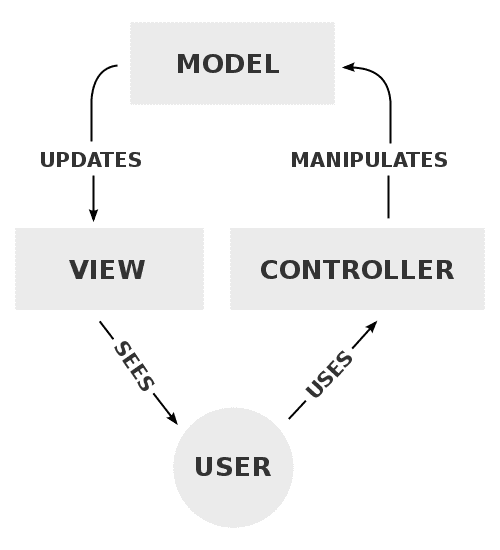
- Model
- Represents the business data and logic that is specific to your application
- In optimal cases, updates to the model automatically notify observers, e.g. the View
- This is the only layer that should directly interact with persistent data (e.g. database, file store, etc).
- Controller
- Layer that acts as worker / glue between Model and View
- Another way to think of this is as a request broker
- Pass updates in Model to view, and pass requests from View to modify data (CRUD) to Model
- Layer that acts as worker / glue between Model and View
- View
- The "presentation" layer, only concerned with the final display output
Where do routes fit in?
TLDR: Routes are another entrypoint to controllers, like Views, and should pass the request to the appropriate controller methods, while optionally performing some request logic and/or formatting the response.
Routes should not directly modify business data or perform business logic.
In a lot of web applications, you deal with (virtual) routing, where your file structure does not mirror the URL in the browser, but your app routes the request to the right code. In an OOP lang/framework, you might have entirely separate classes and methods for routing.
In general, routes are coupled fairly closely with controllers, but should be considered a distinct layer, which can sit between the browser and the controller, just like View.
In terms of actual code, routes are mainly responsible for just calling controller methods, so it is not uncommon to see something that is just a wrapper around controller methods:
Pseudo-code:
router.post('/user', (req, res) => {
return UserRouter.create();
})
// Could be separate file
const userControl = new UserController();
class UserRouter {
public static create(req, res) {
return userControl.create(req);
}
}However, routes can also contain some logic, but you should be careful to keep business data logic in Models. The kind of logic that is common to see in routes, and is OK, is things like:
- Checking for authentication
- Request validation
- Request throttling / blocking
- Request standardization
- Response formatting
- Formatting the data from the Model layer before returning
- Example: Converting to JSON
- Many, many, more examples
More resources
- MDN - Express Tutorial - Part 4: Routes and Controllers
Library file types
| Stat/Dyn | OS | MinGW | MSVC |
|---|---|---|---|
| Static | Win / Unix | .a |
.lib |
| Dynamic | Win | .dll |
.dll |
| Dynamic | Unix | .so |
NA |
.DLL = Dynamic-Link Library. Windows specific
.so = Shared Object. Linux equivalent of DLL
.a | .lib = Static library file
You can break down these types into the two major categories:
- Declarative:
.a,.lib- Header (
.h) files count as these too - The key is that these files declare, or describe things (classes, functions, members, etc), but do not actually have the code to run them.
- Implementation:
.dll,.so.cppis the main one everyone knows- The key is that these files actually contain the implementation code - the code that actually "does things", like functions - as opposed to those files that describe them
Additional reading:
- S/O: Difference between .so, .a, ...
- S/O: Why are static and dynamic linkable libraries so different
Finding DLL Dependents
There are several tools on Windows that you can use to try and figure out which DLLs a program is dependent on:
- Windows Process Explorer / SysInternals
- Make sure to turn on the Lower Pane for the DLL view
- Dependency Walker
DUMPBIN//DEPENDENTS
Big O Notation
Cheatsheets
- https://github.com/aspittel/coding-cheat-sheets/blob/master/fundamentals/big_o_notation.md
- https://dev.to/jainroe/the-ultimate-guide-to-big-o-notation--learning-through-examples-5ecp
- https://medium.com/@albertgao/everything-you-need-to-know-about-big-o-notation-5436d2702199
- https://lukasmestan.com/simple-guide-to-big-o-notation/
- https://dev.to/kritirai/the-big-o-notation-2cep
- https://medium.com/@johnteckert/big-o-no-650ec9cacaa2
- Good quick intro vids:
- Fireship: Big-O Notation in 100 Seconds (YouTube)
- Why My Teenage Code was Terrible: Sorting Algorithms and Big O Notation (YouTube)
- HackerRank - Big O Notation (YouTube) (Basics)
- Great S/O Answers:
- Wikipedia: Table showing notation, name, and examples
What is Big O Notation
"Big-O notation is a relative representation of the complexity of an algorithm."
A more results-driven answer is that Big O Notation is a representation of how well, on the basis of few operations, an algorithm scales based on input size alone.
Quick example:
A short example is simply echoing back an array, versus logging something special for each input. E.g.:
const myAlg = (a) => console.log(a)is O(1)const myAlg = (a) => a.forEach((e,i) => {console.log('Value = ' + e + ', Index = ' + i)})is O(n)
The above example ignores the overhead of
console.log()and makes some probably bad assumptions, and really is just for illustrative purposes.
Table
| Complexity | Common Name | N=1 | N=10 | N=100 | Common Examples |
|---|---|---|---|---|---|
| O(1) | Constant | 1 | 1 | 1 | Picking an element off an arraygetLast = (a) => a[a.length-1]; |
| O(log N) | Logarithmic | 0 | 2 | 5 | Binary search! NOTE: The base is not specified for log, but it also doesn't really matter due to Big O being about relative scaling. |
| O(N) | Linear | 1 | 10 | 100 | Standard for loopechoArr = (a) => a.forEach(e => console.log(e)) |
| O(N log N) | Linearithmic / Loglinear | 0 | 20 | 461 | "Divide and Conquer" type algorithms. For example, Merge Sort. Also FFT. Imagine doing binary search on both sides at the same time... |
| O(N²) | Quadratic | 1 | 100 | 10000 | for loop inside a for loop - recursion |
| O(2ᶰ) | Exponential | 1 | 1024 | 1267650600228229401496703205376 | Brute force, recursion, calculating Fibonacci numbers, etc. |
| O(N!) | Factorial | 1 | 3628800 | 9.3e+157 (HUGE!) | Solving the "Traveling Salesman Problem" with brute force Also, bad programming, like BOGO sort lol |
Where
const ais an array.
Adding vs Multiplying vs Multiple Terms
Basic rules are:
- Loop inside loop = multiply
- Loop outside loop = add
- But see notes on dropping all but highest
Important reminders:
- Equal O Notation does not mean equal performance - it just means the performance scales the same way
- Given function A with O(n) and function B with O(n), function B might actually outperform function A by hours, but both scale in the same way (linear) with input
- This is also why you drop multipliers - like
O(2n)is really justO(n), because you are interested in relative performance, where having a constant2is irrelevant information- This is sometimes called "dropping non-dominate terms"
- A single bottleneck can raise the Big O complexity of an entire process; you can't go faster than the slowest point
- Always take the worst-case as the value
- Technically, it is more like adding them (at least the time), but given how the scales compare, usually the least performant is chewing up the majority
- Kind of like how if you are paying $/foot of a cable, they probably don't include sales tax, given how the majority of your total price is not made up by it
nis just a placeholder variable, for input- Your input could be anything and everything
Algorithms
Algorithms - Resources / Cheatsheets
- Algorithm Visualizer (AWESOME)
- Visualizes how an algorithm sorts / finds / manipulates data
- Visualization is side by side with code!
- Offers different languages - JS, C++, Java
- trekhleb/javascript-algorithms
- Master cheatsheet / repo of Algorithm explanations and examples using JavaScript
- "Computer Science in JavaScript"
- Similar to above, CS concepts, algorithms, etc - explored through JS
- Maintained by Nicholas Zakas (author of Principles of Object-Oriented Programming in JavaScript)
- basarat/algorithms
- TS + JS
- FreeCodeCamp - JS Algorithms and Data Structures
- Back To Back SWE
- YouTube Channel
- GitHub repo (legacy)
- Website (paid)
Also relevant: Job Search: Interview Challenges / Prep
Partial breakdown
- Binary Search:
O(log N)- Resources:
- HackerRank: Binary Search (YouTube)
- How it works:
-
Binary search requires that the input is already sorted!
- Basics:
- Start with the middle of the input. Divide in half, and discard the half that the input cannot lie in
- Keep splitting in half
-
- Resources:
- @TODO: Add more...